
Spark VS Flink 大資料該怎麼選?
可執行在成千上萬的節點上Flink在JVM內部實現了自己的記憶體管理支援迭代計算支援程式自動最佳化:避免特定情況下Shuffle、排序等昂貴操作,中間結果進行快取API支援,對Streaming資料類應用,提供DataStream API,...
可執行在成千上萬的節點上Flink在JVM內部實現了自己的記憶體管理支援迭代計算支援程式自動最佳化:避免特定情況下Shuffle、排序等昂貴操作,中間結果進行快取API支援,對Streaming資料類應用,提供DataStream API,...

3、不擅長DAG(有向圖)計算多個應用存在依賴關係,後一個應用的輸入是前一個應用的輸出,在這種情況下,MapReduce不是不能做,而是每個MapReduce的輸出結果都會 寫入到磁碟,會造成大量的磁碟IO,效能低下MapReduce 程序...

2.大資料框架IBM Streams :分散式處理和實時分析平臺,使用了許多大資料生態系統中的流行技術,Kafka,HDFS,Spark等等Apache Hadoop:分散式處理框架,集成了MapReduce(並行處理),YARN(作業排程...

HDFS和HBase給本地的impalad例項提供資料訪問各個impalad向協調器impalad返回資料,然後由協調器impalad向client傳送結果集應用場景Impala的計算能力很強實時性很高,適用於實時資料分析,因為不支援資料存...

7版本只為了編譯一個dylib庫而已...

兩年後的2006年,Doug Cutting將這些大資料相關的功能從Nutch中分離了出來,然後啟動了一個獨立的專案專門開發維護大資料技術,這就是後來赫赫有名的Hadoop,主要包括Hadoop分散式檔案系統HDFS和大資料計算引擎MapR...

Hadoop的核心配置透過兩個xml檔案來完成:1,hadoop-default...

sh 配置export SPARK_HISTORY_OPTS=“-Dspark...

這裡提到要適當瞭解Hadoop是因為Spark在實際工作中,在載入資料和儲存資料的時候,也是會使用到HDFS的,瞭解Yarn煩人基礎知識也是必須的,Cloudera官方推薦使Spark on Yarn的叢集模式...
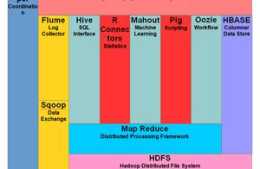
• 可擴充套件性HADOOP叢集透過增加附加群集節點可以容易地擴充套件到任何程度,並允許大資料的增長...

(5)它沒有域名,最關鍵的是它完全是匿名,交易雙方都是匿名,而且貨幣是比特幣brave瀏覽器(1)Brave瀏覽器電腦版基於Chromium核心開發(2)能夠攔截網頁廣告,還擁有追蹤保護、 HTTPS Everywhere等功能(3)提供的...

例如,上述資料的一個對映器任務產生的結果如下所示:(多倫多,20歲)(惠特比25歲)(紐約22歲)(羅馬33歲)讓我們假設其他四個對映器任務(在這裡未顯示的其他四個檔案上工作)產生以下中間結果:(多倫多,18歲)(惠特比,27歲)(紐約,3...

搭建Hadoop的環境準備實驗的環境:1、安裝Linux、JDK2、配置主機名、免密碼登入3、約定:安裝目錄:/root/training安裝:1、解壓 : tar -zxvf hadoop-2.4.1.tar.gz -C /root/tr...

org/2、特點:(*)快(*)易用:Java、Scala、Python(*)生態系統:通用性: Spark Core、Spark SQL、Spark StreamingMLLib、GraphX(*)相容:HDFS、Hive、HBase3、...

三.要做技術的主人最後我希望我們新時代所有的大資料開發者,我們使用Hadoop等大資料技術之前,一定要要先了解它們、學習它們的思想、掌握它們的技巧,而不是當別人交給我們的需求時候我們才去查詢資料...

CASSANDRAApache Cassandra 是一款免費的大資料分析工具,旨在跨許多商品伺服器處理大量資料,提供高可用性...

Hadoop 是一個框架Hadoop 適合處理大規模資料Hadoop 被部署在一個叢集上Hadoop的核心生態圈:Hadoop 是一個開源的高效雲計算基礎架構平臺,其不僅僅在雲計算領域用途廣泛,還可以支撐搜尋引擎服務,作為搜尋引擎底層的基礎...