背景
Hadoop大資料生態系統重要的2個框架Apache Hive和Impala
,用於在HDFS和HBase上進行大資料分析。
但Hive和Impala之間存在一些差異
,Hadoop生態系統中的SQL分析引擎的競爭
,Impala 與Hive都是構建在Hadoop之上的資料查詢工具各有不同的側重適應面,但從客戶端使用來看Impala與Hive有很多的共同之處
。本文中我們會來對比兩種技術Impala vs Hive區別?
Apache Hive
介紹
Hive最早由Facebook開發,後來2008年貢獻給Apache軟體基金會
,
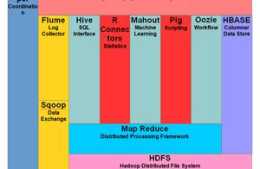
Apache Hive™是開源的一個在Hadoop叢集之上執行的開源資料倉庫和分析包,使用SQL語法讀取Hadoop資料,分析儲存在分散式儲存中HDFS或者HBase資料庫中的大型資料集
。此外,Hive的用途非常廣泛,因為它支援分析儲存在Hadoop的HDFS和其他相容檔案系統中的大量資料集。像亞馬遜S3。Hive指令碼使用類似SQL的語言,稱為Hive QL(查詢語言),它抽象程式設計模型並支援典型的資料倉庫互動。Hive使開發者能夠避免接觸底層機制,如(如Java)中的有向非迴圈圖(DAG)或MapReduce程式編寫Tez作業,降低複雜性。

優缺點
優點:
提供索引加速分析處理,Hive支援多種型別的儲存。如純文字,RCFIle,HBase,ORC。
Hive支援SQL之類的查詢,
而避免了寫 MapReduce 程式來分析資料
,提供快速開發的能力(簡單、容易上手)。
Hive優勢在於處理大資料,對於處理小資料沒有優勢,因為Hive的執行延遲比較高。
Hive支援使用者自定義函式,使用者可以根據自己的需求來實現自己的函式(UDF)。
Hive元資料,可放在關係型資料庫中,支援derby、mysql
缺點:
Hive的HQL表達能力有限
迭代式演算法無法表達遞迴演算法
資料探勘方面不擅長(資料探勘和演算法機器學習)
Hive的效率比較低
Hive自動生成的MapReduce作業,通常情況下不夠智慧化
Hive調優比較困難,粒度較粗(快)
Hive 本身並不提供資料的儲存功能,資料一般都是儲存在 HDFS 上的(對資料完整性、格式要求並不嚴格)
Hive 是專為 OLAP(線上分析處理) 設計,不支援事務
體系架構
Hive是C/S模式,Hive架構包括如下元件:CLI(command line interface)、JDBC/ODBC、Thrift Server、Hive WEB Interface(HWI)、Metastore和Driver(Complier、Optimizer和Executor)
Driver:核心元件
。整個Hive的核心,該元件包括Complier、Optimizer和Executor,它的作用是將我們寫的HQL語句進行解析、編譯最佳化,生成執行計劃,然後呼叫底層的MapReduce計算框架。
Metastore:元資料服務元件。
這個元件儲存Hive元資料,放在關係型資料庫中,支援derby、mysql。
ThriftServers:
提供JDBC和ODBC接入的能力,它用來進行可擴充套件且跨語言的服務的開發,hive集成了該服務,能讓不同的程式語言呼叫hive的介面。
CLI:
command line interface,命令列介面
Hive WEB Interface(HWI):
hive客戶端提供了一種透過網頁的方式訪問hive所提供的服務。這個介面對應hive的hwi元件(hive web interface)

Hive的工作原理如下:

UI呼叫Drive的execute介面(1)
Drive建立一個查詢的Session事件併發送這個查詢到Compiler,Compiler收到Session生成執行計劃(2)
Compiler從MetaStore中獲取一些必要的資料(3,4)
在整個Plan Tree中,MetaStore用於查詢表示式的型別檢查,以及根據查詢謂語(query predicates)精簡partitions 。該Plan由Compiler生成,是一個DAG(Directed acyclic graph,有向無環圖)執行步驟,裡面的步驟包括map/reduce job、metadata 操作、HDFS上的操作,對於map/reduce job,裡面包含map operator trees和一個reduce operator tree(5)
提交執行計劃到Excution Engine,並由Execution Engine將各個階段提交個適當的元件執行(6,6。1,6。2 , 6。3)
在每個任務(mapper / reducer)中,表或者中間輸出相關的反序列化器從HDFS讀取行,並透過相關的操作樹進行傳遞。一旦這些輸出產生,將透過序列化器生成零時的的HDFS檔案(這個只發生在只有Map沒有reduce的情況),生成的HDFS零時檔案用於執行計劃後續的Map/Reduce階段。對於DML操作,零時檔案最終移動到表的位置。該方案確保不出現髒資料讀取(檔案重新命名是HDFS中的原子操作),對於查詢,臨時檔案的內容由Execution Engine直接從HDFS讀取,作為從Driver Fetch API的一部分(7,8,9)
應用場景
Hive在Hadoop中扮演資料倉庫的角色
。Hive新增資料的結構在HDFS(Hive superimposes structure on data in HDFS),並允許使用類似於SQL語法進行資料查詢。
Hive更適合於資料倉庫的任務,主要用於靜態的結構以及需要經常分析的工作
。Hive與SQL相似促使其成為Hadoop與其他BI工具結合的理想交集。Hive的執行延遲比較高,Hive優勢在於處理大資料,對於處理小資料沒有優勢,因為Hive的執行延遲比較高,因此Hive常用於資料分析,對實時性要求不高的場合,適用於日誌分析:pv,uv統計,多維度資料分析以及海量結構化資料離線分析。
Apache Impala
介紹
Impala是一個大規模並行處理引擎,是一個開源引擎。它要求將資料庫儲存在執行Apache Hadoop的計算機群集中。這是一個SQL引擎,由Cloudera在2012年推出,後來貢獻給了apache。
Hadoop程式設計師可以以出色的方式在Impala上執行其SQL查詢,它被認為是一種高效的引擎,因為它在處理之前不會移動或轉換資料,該引擎可以輕鬆實現。Impala的資料格式、元資料、檔案安全性和資源管理與MapReduce相同。它具有Hadoop的所有特質,還可以支援多使用者環境。

優缺點
優點:
基於記憶體運算,不需要把中間結果寫入磁碟,省掉了大量的I/O開銷,能夠對PB級資料進行互動式實時查詢、分析。
無需轉換為Mapreduce,直接訪問儲存在HDFS,HBase中的資料進行作業排程,速度快。
使用了支援Data locality的I/O排程機制,儘可能地將資料和計算分配在同一臺機器上進行,減少了網路開銷。
支援各種檔案格式,如純文字,RCFIle 、SEQUENCEFILE 、Parquet
具有資料倉庫的特性,相容HiveSQL,可對hive資料直接做資料分析
。
缺點:
對記憶體的依賴大,且完全依賴於hive。
實踐中,分割槽超過1萬,效能嚴重下降。
只能讀取文字檔案,而不能直接讀取自定義二進位制檔案。
每當新的記錄/檔案被新增到HDFS中的資料目錄時,該表需要被重新整理
體系架構
Impala是在Hadoop叢集中的許多系統上執行的MPP(大規模並行處理)查詢執行引擎。與傳統儲存系統不同,impala與其儲存引擎解耦。Impala沒有再使用緩慢的Hive+MapReduce批處理,而是透過使用與商用並行關係資料庫中類似的分散式查詢引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分組成)
,可以直接從HDFS或HBase中用SELECT、JOIN和統計函式查詢資料,從而大大降低了延遲。
它有三個主要元件,即Impala daemon(Impalad)、StateStore daemon(statestored) 、Catalog daemon(catalogd),StateStore和Catalog是需要通訊的,所以,搭建時,這兩個是放在一臺主機上,從而使之通訊不需走網路請求。
Impala Daemon:
接收client、hue、jdbc或者odbc請求、Query執行並返回給中心協調節點;子節點上的守護程序,負責向statestore保持通訊,彙報工作。
StateStore Daemon:
檢查叢集各個節點impala daemon的健康狀態,同步節點資訊;負責Query的排程。
Catlog Daemon
:
將sql語句做出的元資料變化通知給叢集的各個節點;接收來自StateStore的所有請求。
Impala的工作原理如下:

客戶端透過ODBC、或者Impala shell向Impala叢集中的任意節點發送SQL語句,這個節點的impalad例項作為這個查詢的協調器(coordinator)
Impala解析和分析這個查詢語句來決定叢集中的哪個impalad例項來執行某個任務。
HDFS和HBase給本地的impalad例項提供資料訪問
各個impalad向協調器impalad返回資料,然後由協調器impalad向client傳送結果集
應用場景
Impala的計算能力很強實時性很高,適用於實時資料分析,因為不支援資料儲存,能處理的問題有一定的限制,與Hive配合使用,對Hive的結果資料集進行實時分析

總結
Impala與Hive都是構建在Hadoop之上的資料查詢工具各有不同的側重適應面,但從客戶端使用來看Impala與Hive有很多的共同之處,如資料表元資料、ODBC/JDBC驅動、SQL語法、靈活的檔案格式、儲存資源池等
。
Hive適合於長時間的批處理查詢分析,而Impala適合於實時互動式SQL查詢
,Impala給資料分析人員提供了快速實驗、驗證想法的大資料分析工具。可以先使用Hive進行資料轉換處理,之後使用Impala在Hive處理後的結果資料集上進行快速的資料分析。
比較基礎
Hive
Impala
開發
Apache Software Foundation
開發語言
用JAVA編寫
用 C++ 編寫
處理速度
慢
Impala比Hive塊10到100倍
儲存支援
RC 檔案,ORC
Hadoop、Apache HBase
支援並行處理
NO
YES
MapReduce 支援
YES
NO
Hadoop 安全
不
支援 Kerberos 身份驗證。
容錯
支援
不支援
複雜型別
支援複雜型別。
Impala 不支援複雜型別。
型別
是基於批次的Hadoop MapReduce
更像MPP資料庫
互動式計算
不支援互動式計算。
支援互動式計算。
查詢處理
普遍存在冷啟動的問題
Impala後端程序總是處在啟動狀態
吞吐量
高吞吐量
低吞吐量
推薦閱讀
HTTP vs. MQTT 物聯網通訊協議對比
Cassandra vs. HBase 列式資料庫對比
Spring Cloud vs. Apache Dubbo 微服務框架對比
RPC Style vs. REST Web APIs