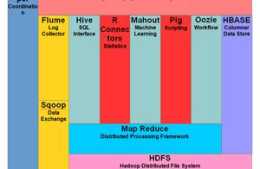
Mapredce定義:
MapReduce是一個分散式運算程式的程式設計框架,是使用者開發(基於Hadoop的資料分析應用)的核心框架。
MapReduce的核心功能是將使用者編寫的業務邏輯程式碼與自帶的預設元件整合成一個完整的分散式運算程式,併發執行在一個Hadoop叢集上。
MapReduce優缺點
1、優點
1。1、易於程式設計
1。2、良好的擴張性
1。3、高容錯
其中一臺機器掛掉,它上面執行的計算任務會自動轉移到另外的機器上執行,不需要人工干預
1。4、適用PB級以上海量資料的離線處理
2、缺點
2。1、不擅長實時計算
2。2、不擅長流式計算
2。3、不擅長DAG(有向圖)計算
多個應用存在依賴關係,後一個應用的輸入是前一個應用的輸出,在這種情況下,MapReduce不是不能做,而是每個MapReduce的輸出結果都會 寫入到磁碟,會造成大量的磁碟IO,效能低下
MapReduce 程序
MrAppMaster:負責整個程式的過程排程和狀態協調
MapTask:負責Map階段的資料處理流程
ReduceTask:負責Reduce階段資料處理流程
常用的資料序列化型別
Java型別 Hadoop Writable型別
boolean BooleanWritable
byte ByteWritable
int IntWritable
float FloatWritable
long LongWritable
double DoubleWritable
String Text
map MapWritable
array ArrayWritable
MapReduce 程式設計規範
Mapper
使用者自定義的Mapper 繼承父類,重寫父類的map() 方法
Mapper 中業務邏輯寫在map() 方法內
Mapper 的輸入型別和輸出型別都是 K V對的形式,
Reduce
使用者自定義的Reduce 繼承父類,重寫父類的reduce() 方法
Reduce 業務邏輯寫在reduce() 方法內
Reduce的輸入型別,輸出型別都是K V對的形式
Reduce對每組k 呼叫一次reduce() 方法
Driver
相當於yarn叢集的客戶端,用於提交整個程式到yarn 叢集,提交時封裝了MapReduce程式相關執行引數的job物件
wordCount演練
需求:統計檔案中每個單詞出現的次數,檔案儲存在HDFS中,路徑和內容如下:
[root@bbx hadoop-3。1。3]# bin/hdfs dfs -ls -R /home/input/-rw-r——r—— 1 root supergroup 30 2020-05-02 17:05 /home/input/name[root@bbx hadoop-3。1。3]# bin/hdfs dfs -cat /home/input/name2020-05-04 16:47:12,295 INFO sasl。SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = falseaa bb ssaa cc ddbbccddee
maven依賴
<?xml version=“1。0” encoding=“UTF-8”?>
自定義mapper
package com。bbx。wcdemo;import org。apache。hadoop。io。IntWritable;import org。apache。hadoop。io。LongWritable;import org。apache。hadoop。io。Text;import org。apache。hadoop。mapreduce。Mapper;import java。io。IOException;public class WCMapper extends Mapper
自定義reduce
package com。bbx。wcdemo;import org。apache。hadoop。io。IntWritable;import org。apache。hadoop。io。Text;import org。apache。hadoop。mapreduce。Reducer;import java。io。IOException;public class WCReduce extends Reducer
Driver 驅動
package com。bbx。wcdemo;import org。apache。hadoop。conf。Configuration;import org。apache。hadoop。fs。Path;import org。apache。hadoop。io。IntWritable;import org。apache。hadoop。io。Text;import org。apache。hadoop。mapreduce。Job;import org。apache。hadoop。mapreduce。lib。input。FileInputFormat;import org。apache。hadoop。mapreduce。lib。output。FileOutputFormat;import java。io。IOException;public class WcdemoApplication { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job。getInstance(configuration); job。setJarByClass(WcdemoApplication。class); job。setMapperClass(WCMapper。class); job。setReducerClass(WCReduce。class); job。setMapOutputKeyClass(Text。class); job。setMapOutputValueClass(IntWritable。class); job。setOutputKeyClass(Text。class); job。setOutputValueClass(IntWritable。class); FileInputFormat。setInputPaths(job,new Path(args[0])); FileOutputFormat。setOutputPath(job,new Path(args[1])); job。waitForCompletion(true); }}
叢集環境執行——(輸出路徑不能存在)
hadoop jar wcdemo-0。0。1-SNAPSHOT。jar com。bbx。wcdemo。WcdemoApplication /home/input/ /home/output